Prediciendo arquitectura
Marcelo Bernal
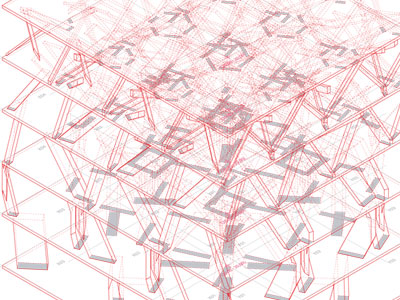
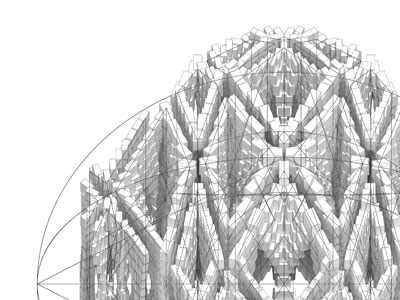
La noción de predicción en arquitectura contiene la siguiente paradoja: mientras más simulaciones computacionales se producen, menos simulaciones se requieren, ya que se puede proyectar a partir de las correlaciones históricas entre inputs y outputs. Basada en modelos de machine learning derivados de la inteligencia artificial, esta tendencia propone no solo resultados con altos niveles de precisión estadística, superiores a cualquier tipo de intuición, sino también su disponibilidad casi instantánea. Para entender las raíces de esta práctica primero hay que entender la noción de espacio de diseño. Esta corresponde al universo de las posibles variaciones de un modelo a partir de diferentes combinaciones de sus inputs de entrada, tanto geométricos como de propiedades materiales, así como los relativos a su programación. En este sentido, consistente con sus orígenes en las teorías de la complejidad que influenciaron a la disciplina en los años 90, un modelo representa un potencial, y cada variación o instanciación, su actualización. Sin embargo, el cambio fundamental introducido es que un modelo fundado en la predicción opera con grandes poblaciones de alternativas, todas ellas derivadas de una única arquitectura, la cual reside en el modelo mismo, y no ya en el objeto resultante. Se trata de una estética de las relaciones, y no de las formas.
En la construcción y exploración de los espacios de diseño convergen teorías de diseño generativo, performance y toma de decisiones. Su implementación se sustenta en una integración de software de diseño, simulación, análisis estadístico y visualización de información. Este software no es otra cosa que conocimiento sistematizado y vuelto disponible para ser reutilizado, algo profundamente humano. Los métodos de diseño generativo se combinan con los de simulación en técnicas de análisis paramétrico, que no implican otra cosa que el análisis simultáneo de cada una de las variaciones. No obstante, cuando el modelo geométrico se conecta a una variedad de modelos de análisis, el espacio de diseño se vuelve multi-criterio, y adquiere la capacidad de representar todo tipo de conflictos entre los diferentes aspectos a evaluar. Esta abundancia de información presenta al menos dos desafíos fundamentales: manipular grandes poblaciones de millones de opciones y discriminar dónde reside el valor de cada una.
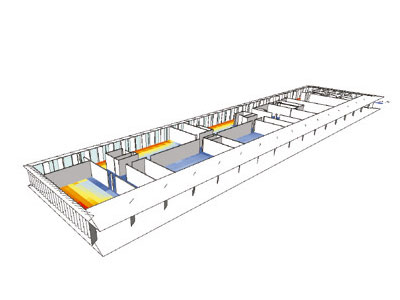
Para lo primero se recurre a métodos estadísticos, que permiten seleccionar muestras del espacio total, correlacionar inputs y outputs, por ejemplo, a través del análisis de sensibilidad o de modelos de regresión, y proyectar el impacto que cada uno de ellos tiene en los indicadores por aspecto. Sin embargo, en contextos complejos como la práctica del diseño, una serie de indicadores de performance tales como radiación, energía, confort térmico, emisiones, iluminación, ventilación natural, vistas, costos de construcción, retornos de inversión, costos de operación, campos visuales o conectividad, por nombrar algunos de los más genéricos, no representan directamente un valor en sí, ya que diferentes ponderaciones de cada uno pueden determinar que distintas variaciones se presenten como opción dependiendo del escenario. Es precisamente aquí donde las técnicas de visualización de la información se combinan con las de análisis de datos, jugando un importante rol en modelar el subjetivo mundo de la toma de decisiones en problemas de diseño multidimensionales. Superada la ansiedad de exuberancia formal de décadas pasadas, la maquinaria computacional de exploración de espacios de diseño está produciendo tal cantidad de información, alimentando, a su paso, métodos predictivos que establecen un nuevo diálogo con la intuición en diseño.